# 基础语法
# 安装系统环境
在讲述java的基础语法的时候首先我们需要进行Java开发环境的配置。
首先是下载JDK,设置环境变量(设置了系统变量可以让我们在任何目录下可以执行Java相关的命令)。
# 命令行工具
javac Welcome.java //编译源代码
java Welcome //执行编译之后的class文件
2
3
# 注释
方式一:/*我是注释*/
方式二://我是注释
2
3
4
# 数据类型
# 基本类型
| 数据类型 | bit位 | 取值范围 | 示例 | 包装类型 |
|---|---|---|---|---|
| boolean | 1 | 一个bit位,1,0,分别true false | true/false | Boolean |
| byte | 8 | -128~127 | 56 | Byte |
| char | 16 | 每个 char 表示一个 Unicode 码点,即从 \u0000 到 \uFFFF | A | Character |
| short | 16 | -32768 - 32767 | 100 | Short |
| int | 32 | -2147483648 - 2147483647 (正好超过 20 亿) | 100 | Integer |
| long | 64 | -9223372036854775808 - 9223372036854775807 | 100L | Long |
| float | 32 | 大约 ± 3.40282347E+38F (有效位数为 6 ~ 7 位) | 3.14F | Float |
| double | 64 | 大约 ± 1.79769313486231570E+308 (有效位数为 15 位> | 3.14D | Double |
关于char类型与中文的关系
在Java中,char类型是16位无符号数据类型,用来表示Unicode字符。理论上,它应该能够表示包括汉字在内的所有字符。然而,由于早期Unicode标准的限制(即使用2字节表示字符),Java的char类型被设计为固定大小的16位,这足以覆盖最初的Unicode平面(Basic Multilingual Plane, BMP),包括大部分常用汉字。
但是,随着Unicode标准的发展,一些较少使用的字符(包括部分汉字)被分配到了辅助平面(Supplementary Planes),这些字符需要超过16位来表示。因此,单个char无法直接表示这些位于辅助平面的字符。对于这种情况,Java使用了一种称为“代理对”(surrogate pairs)的技术,通过两个char值组合起来表示一个字符。
总结来说,在Java中,char类型可以直接表示大多数常见的汉字(属于BMP内的汉字),但对于那些位于Unicode辅助平面的特殊或生僻汉字,则需要使用两个char值组成的代理对才能正确表示。如果你的工作仅涉及现代汉语中的常用汉字,那么使用char类型来处理单个汉字是没有问题的。
汉字字符串的length 得到的结果和汉字个数一定对等吗?
在Java中,使用String类的length()方法获取字符串长度时,得到的结果并不总是与字符串中汉字(或其他字符)的实际个数对等。这是因为length()方法返回的是组成该字符串的char值的数量,而不是直观上的字符数量。
对于大多数常见的汉字,它们位于Unicode的基本多语言平面(BMP)内,每个汉字占用一个char(即16位),在这种情况下,length()方法返回的值确实等于字符串中字符(包括汉字)的数量。
然而,对于那些位于Unicode辅助平面的特殊或生僻汉字(通过代理对表示),以及其他一些需要超过16位编码的字符,它们由两个char值组成的代理对来表示。这意味着这些字符会使得length()方法返回的值比实际字符数大,因为每个这样的字符会贡献两个char值。
此外,如果字符串包含其他类型的Unicode标量值,比如表情符号(某些情况下可能由多个char值组成),同样可能导致length()方法返回的值与实际字符数量不一致。
为了准确计算字符串中的字符数,包括正确处理上述情况,可以使用String类的codePointCount(int beginIndex, int endIndex)方法,它能够根据码点(code point)而非char值来计数,从而提供更精确的字符数量统计。例如:
String str = "你好😉"; // 包含2个汉字和一个双字符的表情符号
int lengthInChars = str.length(); // 返回4,因为表情符号占用了2个char
int actualLength = str.codePointCount(0, str.length()); // 返回3,准确的字符数量
2
3
这样你就能得到符合直觉的字符总数了。
# 引用类型
- 类(Class):这是最常用的引用类型,包含了字段、方法、构造函数等成员,用于创建对象实例。
- 接口(Interface):接口定义了一组没有实现的方法,可以由实现了该接口的类来提供具体实现。接口允许Java支持多态性的一种方式。
- 数组(Array):无论是基本数据类型的数组还是对象的数组,都是引用类型。数组大小固定,一旦被创建后,其长度不能改变。
- 枚举(Enum):枚举类型是一种特殊的类,它限制变量只能为若干个预定义的常量之一。枚举有助于增强代码的可读性和健壮性。
- 注解(Annotation):虽然注解本身通常不被视为传统意义上的“类型”,但它们确实属于引用类型的一种形式。注解可以用来添加元数据到代码元素上,如类、方法、变量等。
这些引用类型都具有以下共同特点:
- 它们都在堆内存中分配。
- 通过引用(类似于指针的概念,但更安全)访问它们的内容。
- 支持继承和多态性。
- 在没有任何引用指向它们时,可以通过垃圾回收机制自动清理,从而释放内存。
# 装箱拆箱
自动装箱(Autoboxing)和自动拆箱(Unboxing)是Java语言为了简化基本数据类型与它们对应的包装类之间的转换过程而引入的特性。这些特性在Java 5中被引入,使得开发人员可以更方便地在基本数据类型和其对应的引用类型之间进行转换,减少了代码量,并提高了代码的可读性和简洁性。
# 自动装箱
自动装箱是指将基本数据类型自动转换为对应的包装类对象的过程。例如,将int类型的值转换为Integer对象。在Java中,当你将一个基本数据类型赋值给一个需要对象类型的变量时,编译器会自动执行装箱操作。
示例:
Integer a = 10; // 自动装箱, 实际上是 Integer a = Integer.valueOf(10);
这里,整型字面量10被自动转换为Integer对象。
# 自动拆箱
自动拆箱则是相反的过程,指的是将包装类对象自动转换为其对应的基本数据类型的过程。例如,将Integer对象转换为int类型。当一个包装类对象被用在一个需要基本数据类型的地方时,编译器会自动执行拆箱操作。
示例:
Integer a = new Integer(10);
int i = a; // 自动拆箱, 实际上是 int i = a.intValue();
2
这里,Integer对象a被自动转换为int类型。
# 注意事项
虽然自动装箱和拆箱极大地方便了开发者的编码工作,但在使用时也需要注意以下几点:
性能问题:频繁的装箱和拆箱操作可能会影响程序的性能,因为每次操作都会涉及到对象的创建或销毁。
比较操作:自动装箱可能导致意外的行为,特别是在进行相等性比较时。比如,两个不同的
Integer对象即使包含相同的数值,在使用==进行比较时也可能返回false,因为这比较的是对象引用而非内容。因此,对于对象的内容比较,应使用equals()方法。示例:
Integer x = 100; Integer y = 100; System.out.println(x == y); // true,由于缓存机制 Integer a = 200; Integer b = 200; System.out.println(a == b); // 可能为false,取决于JVM实现1
2
3
4
5
6
7
虽然标准的Java规范定义了
Integer缓存的范围(-128到127),但具体的JVM实现可以在一定范围内调整这个缓存的大小。某些JVM实现可能允许用户通过特定的参数或配置来扩展这个缓存范围。如果某个JVM实现将缓存范围扩展到包含200,则a == b可能会返回true,因为它会返回相同的缓存对象。然而,这种行为并不是所有JVM实现的标准部分,也不建议依赖于这种行为,因为它是实现细节的一部分,并且可能会因不同的JVM版本或配置而变化。
理解和正确使用自动装箱与拆箱功能,可以帮助开发者编写出更加简洁、易读的代码,但同时也要注意避免因不当使用而导致的问题。
# 关键字
有特殊含义的单词,能用的48个,不可以使用的goto,const等关键字来定义变量。
# final
# 1. 修饰属性
声明数据为常量,可以是编译时常量,也可以是在运行时被初始化后不能被改变的常量。
- 对于基本类型,final 使数值不变;
- 对于引用类型,final 使引用地址不变,也就不能引用其它对象,但是被引用的对象本身属性是可以修改的。
final int x = 1;
// x = 2; // cannot assign value to final variable 'x' 不可以再次赋值
final A y = new A();
y.a = 1;
2
3
4
# 2. 修饰方法
- 定义:当你用
final修饰一个方法时,意味着这个方法不能被子类重写。 - 用途:通常用于防止子类改变基类中关键方法的行为,确保方法的实现不会被意外修改。
示例:
class Parent {
final void show() {
System.out.println("This is a final method.");
}
}
class Child extends Parent {
// 以下代码会导致编译错误,因为show()方法是final的
// void show() {
// System.out.println("Trying to override final method.");
// }
}
2
3
4
5
6
7
8
9
10
11
12
private 方法
- 定义:
private方法只能在其定义的类内部访问,不能被其他类(包括子类)访问。 - 隐式
final:虽然private方法没有显式地使用final关键字,但由于它们的访问权限限制,它们实际上不能被子类重写。任何在子类中定义的具有相同签名的方法都不会被视为重写,而是定义了一个全新的方法。
示例:
class Parent {
private void display() {
System.out.println("This is a private method in Parent.");
}
}
class Child extends Parent {
void display() {
System.out.println("This is a new method in Child, not overriding Parent's method.");
}
}
public class Main {
public static void main(String[] args) {
Parent p = new Parent();
p.display(); // 编译错误:display() has private access in Parent
Child c = new Child();
c.display(); // 输出: This is a new method in Child, not overriding Parent's method.
Parent pc = new Child();
// pc.display(); // 编译错误:display() has private access in Parent
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
在这个例子中,尽管Child类中定义了一个名为display的方法,但它并不是对Parent类中的private display方法的重写。相反,它是一个独立的新方法,仅存在于Child类中。
总结
final方法:明确禁止子类重写该方法。private方法:由于其访问权限限制,也不能被子类重写。如果子类中定义了与父类private方法同名的方法,这将被视为定义一个新的方法,而不是重写父类的方法。
# 3. 修饰类
- 定义:通过在类声明前加上
final关键字,表示该类是最终类,不能被继承。 - 用途:通常用于确保类的实现不会被修改或扩展,保证类的安全性和稳定性。例如,Java标准库中的
String、Integer等类都是final类。
示例:
// 声明一个final类
final class FinalClass {
public void display() {
System.out.println("This is a final class.");
}
}
// 尝试继承FinalClass会导致编译错误
// class ChildClass extends FinalClass { } // 编译错误: 无法继承final类
2
3
4
5
6
7
8
9
在这个例子中,FinalClass被声明为final,因此任何尝试继承它的代码都会导致编译错误。
使用场景
- 安全性:确保某些关键类的行为不被改变,防止恶意或无意的继承和重写。
- 性能优化:对于一些确定不会被继承的类,标记为
final可以让编译器进行更多的优化。 - 设计意图:明确表明该类的设计意图是不可扩展的,帮助开发者理解类的使用方式。:
总结
final关键字修饰类:使该类成为最终类,禁止其他类继承它。- 应用场景:适用于那些需要确保实现不变、防止被继承的关键类,如安全类、工具类等。
通过合理使用final关键字,可以帮助你更好地控制类的层次结构,确保类的设计意图得到正确实现,并提高代码的安全性和可维护性。
# static
# 1. 静态变量
- 静态变量: 又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它;静态变量在内存中只存在一份。
- 实例变量: 每创建一个实例就会产生一个实例变量,它与该实例同生共死。
public class A {
private int x; // 实例变量
private static int y; // 静态变量
public static void main(String[] args) {
// int x = A.x; // Non-static field 'x' cannot be referenced from a static context
A a = new A();
int x = a.x;
int y = A.y;
}
}
2
3
4
5
6
7
8
9
10
11
# 2. 静态方法
静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须有实现,也就是说它不能是抽象方法(abstract)。
public abstract class A {
public static void func1(){
}
// public abstract static void func2(); // Illegal combination of modifiers: 'abstract' and 'static'
}
2
3
4
5
静态方法只能访问所属类的静态字段和静态方法,方法中不能有 this 和 super 关键字。
public class A {
private static int x;
private int y;
public static void func1(){
int a = x;
// int b = y; // Non-static field 'y' cannot be referenced from a static context
// int b = this.y; // 'A.this' cannot be referenced from a static context
}
}
2
3
4
5
6
7
8
9
10
# 3. 静态语句块
静态语句块在类初始化时运行一次。
public class A {
static {
System.out.println("123");
}
public static void main(String[] args) {
A a1 = new A();
A a2 = new A();
}
}
123
2
3
4
5
6
7
8
9
10
11
12
# 4. 静态内部类
非静态内部类依赖于外部类的实例,而静态内部类不需要。
public class OuterClass {
class InnerClass {
}
static class StaticInnerClass {
}
public static void main(String[] args) {
// InnerClass innerClass = new InnerClass(); // 'OuterClass.this' cannot be referenced from a static context
OuterClass outerClass = new OuterClass();
InnerClass innerClass = outerClass.new InnerClass();
StaticInnerClass staticInnerClass = new StaticInnerClass();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
静态内部类不能访问外部类的非静态的变量和方法。
# 5. 静态导包
静态导入的基本语法
import static 包名.类名.静态成员名;
// 或者导入一个类的所有静态成员
import static 包名.类名.*;
2
3
静态导入的作用
减少冗余:当你需要多次调用同一个类的静态成员时,使用静态导入可以避免每次都要写类名前缀。
示例:
// 没有使用静态导入的情况 System.out.println(Math.sqrt(16)); System.out.println(Math.pow(2, 3)); // 使用静态导入后 import static java.lang.Math.*; public class Main { public static void main(String[] args) { System.out.println(sqrt(16)); // 不需要再写Math.sqrt System.out.println(pow(2, 3)); // 不需要再写Math.pow } }1
2
3
4
5
6
7
8
9
10
11
12
13提高代码可读性:当代码中大量使用某个类的静态成员时,静态导入可以使代码看起来更加简洁和直观。
简化常量使用:如果你有一个包含许多常量的类,静态导入可以使这些常量的使用更加方便。
示例:
// 定义一个包含常量的类 public class Constants { public static final int MAX_CONNECTIONS = 100; public static final String DEFAULT_ENCODING = "UTF-8"; } // 使用静态导入 import static Constants.*; public class Main { public static void main(String[] args) { System.out.println("Max connections: " + MAX_CONNECTIONS); // 不需要写Constants.MAX_CONNECTIONS System.out.println("Default encoding: " + DEFAULT_ENCODING); // 不需要写Constants.DEFAULT_ENCODING } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
注意事项
尽管静态导入可以使代码更简洁,但也有一些潜在的问题需要注意:
命名冲突:如果多个静态导入的类中有同名的静态成员,可能会导致命名冲突。因此,在使用静态导入时,应尽量避免这种情况。
示例:
import static java.lang.Math.PI; import static java.lang.Double.NaN; public class Main { public static void main(String[] args) { System.out.println(PI); // 这里不会冲突 System.out.println(NaN); // 这里也不会冲突,但如果两个类都有相同的静态成员名,则会冲突 } }1
2
3
4
5
6
7
8
9代码可读性下降:虽然静态导入减少了代码中的类名前缀,但如果过度使用或不加选择地导入大量的静态成员,可能会使代码变得难以理解,因为读者可能不知道某个静态成员来自哪个类。
滥用风险:静态导入应该谨慎使用,尤其是在大型项目中。如果使用不当,可能会导致代码的可维护性和可读性下降。
总结
静态导入的主要作用是简化对静态成员的访问,减少代码中的冗余,并提高代码的可读性。然而,为了保持代码的清晰性和可维护性,应当合理使用静态导入,避免不必要的复杂性和命名冲突。通常建议只在确实能显著提升代码简洁性和可读性的场景下使用静态导入。
# 6. 初始化顺序
假设我们有一个继承层次结构,并且有如下代码:
//父类
class Parent {
static { System.out.println("Parent static block"); }
static String parentStaticField = initializeStaticField();
static String initializeStaticField() {
System.out.println("Initializing Parent static field");
return "Parent Static Field";
}
{ System.out.println("Parent instance initializer block"); }
String parentInstanceField = initializeInstanceField();
String initializeInstanceField() {
System.out.println("Initializing Parent instance field");
return "Parent Instance Field";
}
public Parent() {
System.out.println("Parent constructor");
}
}
//子类
class Child extends Parent {
static { System.out.println("Child static block"); }
static String childStaticField = initializeStaticField();
static String initializeStaticField() {
System.out.println("Initializing Child static field");
return "Child Static Field";
}
{ System.out.println("Child instance initializer block"); }
String instanceField = initializeInstanceField();
String initializeInstanceField() {
System.out.println("Initializing Child instance field");
return "Child Instance Field";
}
public Child() {
System.out.println("Child constructor");
}
}
//运行
public class Main {
public static void main(String[] args) {
new Child();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
输出结果
Parent static block// 父类静态初始化块被调用
Initializing Parent static field// 初始化父类中的静态字段 parentStaticField
Child static block// 子类静态初始化块被调用
Initializing Child static field// 初始化子类中的静态字段 childStaticField
Parent instance initializer block// 父类实例初始化块被调用
Initializing Parent instance field// 初始化父类中的实例字段 parentInstanceField
Parent constructor// 调用父类的构造函数
Child instance initializer block// 子类实例初始化块被调用
Initializing Child instance field// 初始化子类中的实例字段 instanceField
Child constructor// 调用子类的构造函数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 父类静态成员和静态初始化块
- 执行时机:当类第一次被加载时。
- 内容:包括静态变量的初始化和静态初始化块的执行。
- 顺序:按照它们在类中声明的顺序执行。
- 子类静态成员和静态初始化块
- 执行时机:在父类的静态成员和静态初始化块执行完毕后。
- 内容:包括静态变量的初始化和静态初始化块的执行。
- 顺序:按照它们在类中声明的顺序执行。
- 父类实例成员和实例初始化块
- 执行时机:当创建类的实例时,在调用构造函数之前。
- 内容:包括实例变量的初始化和实例初始化块的执行。
- 顺序:按照它们在类中声明的顺序执行。
- 父类构造函数
- 执行时机:在父类的实例成员和实例初始化块执行完毕后。
- 内容:构造函数中的代码。
- 子类实例成员和实例初始化块
- 执行时机:在父类的构造函数执行完毕后。
- 内容:包括实例变量的初始化和实例初始化块的执行。
- 顺序:按照它们在类中声明的顺序执行。
- 子类构造函数
- 执行时机:在子类的实例成员和实例初始化块执行完毕后。
- 内容:构造函数中的代码。
# 变量命名风格
可以是字符,数字下划线、$、不能以数字开头,不能有特殊符号
不能使用 Java 保留字作为变量名(关键字)
大小写敏感
见名知意,驼峰标识
声明一个变量之后,必须用赋值语句对变量进行显式初始化, 千万不要使用未初始化的变量
# 强制规则
代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束。
- 反例:
_name / __name / $name / name_ / name$ / name__
- 反例:
严禁使用拼音与英文混合的方式,更不允许直接使用中文的方式。
- 说明:正确的英文拼写和语法可以让阅读者易于理解,避免歧义。
- 正例:
alibaba / taobao / youku / hangzhou - 反例:
DaZhePromotion [打折] / getPingfenByName() [评分] / int 某变量 = 3
类名使用UpperCamelCase风格,但以下情形例外:DO / BO / DTO / VO / AO / PO / UID等。
- 正例:
MarcoPolo / UserDO / XmlService / TcpUdpDeal / TaPromotion - 反例:
macroPolo / UserDo / XMLService / TCPUDPDeal / TAPromotion
- 正例:
方法名、参数名、成员变量、局部变量都统一使用lowerCamelCase风格,必须遵从驼峰形式。
- 正例:
localValue / getHttpMessage() / inputUserId
- 正例:
常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长。
- 正例:
MAX_STOCK_COUNT - 反例:
MAX_COUNT
- 正例:
抽象类命名使用Abstract或Base开头;异常类命名使用Exception结尾;测试类命名以它要测试的类的名称开始,以Test结尾。
类型与中括号紧挨相连来表示数组。
- 正例:定义整形数组
int[] arrayDemo; - 反例:在main参数中,使用
String args[]来定义。
- 正例:定义整形数组
POJO类中布尔类型的变量,都不要加is前缀,否则部分框架解析会引起序列化错误。
包名统一使用小写,点分隔符之间有且仅有一个自然语义的英语单词。包名统一使用单数形式,但是类名如果有复数含义,类名可以使用复数形式。
- 正例:应用工具类包名为
com.alibaba.ai.util、类名为MessageUtils
- 正例:应用工具类包名为
杜绝完全不规范的缩写,避免望文不知义。
- 反例:
AbstractClass“缩写”命名成AbsClass;condition“缩写”命名成condi
- 反例:
# 推荐规则
为了达到代码自解释的目标,任何自定义编程元素在命名时,使用尽量完整的单词组合来表达其意。
- 正例:在JDK中,表达原子更新的类名为:
AtomicReferenceFieldUpdater - 反例:变量
int a的随意命名方式。
- 正例:在JDK中,表达原子更新的类名为:
如果模块、接口、类、方法使用了设计模式,在命名时需体现出具体模式。
- 正例:
public class OrderFactory; public class LoginProxy; public class ResourceObserver;1
2
3
- 正例:
接口类中的方法和属性不要加任何修饰符号(public也不要加),保持代码的简洁性,并加上有效的Javadoc注释。
接口和实现类的命名有两套规则:
- 对于Service和DAO类,基于SOA的理念,暴露出来的服务一定是接口,内部的实现类用Impl的后缀与接口区别。
- 正例:
CacheServiceImpl实现CacheService接口。
- 正例:
- 如果是形容能力的接口名称,取对应的形容词为接口名(通常是–able的形式)。
- 正例:
AbstractTranslator实现Translatable接口。
- 正例:
- 对于Service和DAO类,基于SOA的理念,暴露出来的服务一定是接口,内部的实现类用Impl的后缀与接口区别。
# 参考规则
枚举类名建议带上Enum后缀,枚举成员名称需要全大写,单词间用下划线隔开。
- 正例:枚举名字为
ProcessStatusEnum的成员名称:SUCCESS / UNKNOWN_REASON
- 正例:枚举名字为
各层命名规约:
- Service/DAO层方法命名规约
- 获取单个对象的方法用get做前缀。
- 获取多个对象的方法用list做前缀,复数形式结尾如:
listObjects。 - 获取统计值的方法用count做前缀。
- 插入的方法用save/insert做前缀。
- 删除的方法用remove/delete做前缀。
- 修改的方法用update做前缀。
- 领域模型命名规约
- 数据对象:xxxDO,xxx即为数据表名。
- 数据传输对象:xxxDTO,xxx为业务领域相关的名称。
- 展示对象:xxxVO,xxx一般为网页名称。
- POJO是DO/DTO/BO/VO的统称,禁止命名成xxxPOJO。
- Service/DAO层方法命名规约
# 运算符
# 算数运算符
+:加法 两数相加-:减法 两数相减*:乘法 两数相乘/:除法 两数相除(两边都是整型时,进行整型运算)%:取模 两数取余(两个数必须是整数)
int a = 20;
int b = 10;
System.out.println(a + b);//30
System.out.println(a - b);//10
System.out.println(a * b);//200
System.out.println(a / b);//2
System.out.println(a % b);//0
2
3
4
5
6
7
8
注意事项:
- 算式运算符都是二元运算符需要两个操作数
/%的第二个操作数不能为0/:int / int 结果还是int类型,而且会向下取整
# 关系运算符
==:等于!=:不等于<:小于>:大于<=:小于等于>=:大于等于
int num1 = 3;
int num2 = 0;
System.out.println(num1 == num2);//false
System.out.println(num1 != num2);//true
System.out.println(num1 < num2);//false
System.out.println(num1 > num2);//true
System.out.println(num1 <= num2);//false
System.out.println(num1 >= num2);//true
2
3
4
5
6
7
8
注意事项:
- 当需要多次判断时,不能连着写,比如:3 < a < 5,Java程序与数学中是有区别的
# 逻辑运算符
&&:逻辑与(与)||:逻辑或(或)!:逻辑非(非)
# 1.逻辑与 &&
语法规则:表达式1 && 表达式2,左右表达式必须是boolean类型的结果。
相当于现实生活中的且,比如:如果是学生,并且 带有学生证 才可以享受半票。
两个表达式都为真,结果才是真,只要有一个是假,结果就是假。
int a = 1;
int b = 2;
System.out.println(a == 1 && b == 2); // 左为真 且 右为真 则结果为真
2
3
# 2.逻辑或 ||
语法规则:表达式1 || 表达式2,左右表达式必须是boolean类型的结果。
相当于现实生活中的或,比如:买房子交钱时,全款 或者 按揭都可以,如果全款或者按揭,房子都是你的,
否则站一边去。
int a = 1;
int b = 2;
System.out.println(a == 1 || b == 2); // 左为真 且 右为真 则结果为真
2
3
注意:&& 和 || 都是短路逻辑运算符
int a = 1;
int b = 2;
System.out.println(a++ > 0 || b++ >0);//true
system.out.println(a);//2
system.out.println(b);//2
2
3
4
5
短路逻辑运算符:||如果左边为真,右边不执行。
int a = 1;
int b = 2;
System.out.println(a++ < 0 && b++ >0);//true
system.out.println(a);//2
system.out.println(b);//2
2
3
4
5
6
短路运算符:&&如果左边为假,右边不执行。
# 3.逻辑非 !
语法规则:! 表达式
真变假,假变真。
int a = 1;
System.out.println(!(a == 1)); // a == 1 为true,取个非就是false
System.out.println(!(a != 1)); // a != 1 为false,取个非就是true
2
3
# 赋值运算符
用于将值分配给变量。
=:赋值 +=:加并赋值 -=:减并赋值 *=:乘并赋值 /=:除并赋值 %=:取模并赋值 该种类型运算符操作完成后,会将操纵的结果赋值给左操作数。
int x = 10;
x += 3;//13
x -= 3;//10
x *= 3;//30
x /= 3;//10
x %= 3;//1
2
3
4
5
6
注意事项:
赋值运算符都是先把左边的计算完,在赋值给右边。x += 3+5是等价于x = x + (3 + 5)
# 自增、自减运算符
用于增加或减少变量的值。
++:自增 --:自减
int a = 3;
int b = a++;
System.out.println(a);//4
System.out.println(b);//3
int c = 3;
int d = --c;
System.out.println(c);//2
System.out.println(d);//2
2
3
4
5
6
7
8
9
后置++或者–都是先使用变量原来的值,然后在加加或者减减。
前置++或者–都是先加加或者减减,在使用变量的加加减减的值。
注意事项:
如果单独使用,前置和后置没有区别。 只有变量才能使用自增或者自减运算符。 自增/自减运算可以用于整数类型 byte、short、int、long,浮点类型 float、double,以及字符串类型 char。 在 Java 1.5 以上版本中,自增/自减运算可以用于基本类型对应的包装器类 Byte、Short、Integer、Long、Float、Double 和 Character。
# 位运算符
用于执行位级别的操作。
&:按位与|:按位或^:按位异或~:按位非<<:左移>>:带符号右移>>>:无符号右移
# 1.按位与 &
对两个操作数的每个位执行与操作,只有两个操作数的对应位都为1时,结果位才为1。例如,1101 & 1010 的结果是 1000。
# 2.按位或 |
对两个操作数的每个位执行或操作,只要两个操作数的对应位中有一个为1,结果位就为1。例如,1101 | 1010 的结果是 1111。
3.按位异或 ^ 对两个操作数的每个位执行异或操作,只有两个操作数的对应位不相同时,结果位才为1。例如,1101 ^ 1010 的结果是 0111。
重要结论:
- a ^ 0等于a。
- a^a等于0.
# 4.按位非~
对单个操作数的每个位执行非操作,将0变为1,将1变为0。例如,~1101 的结果是 0010。
# 5.左移<<
将操作数的二进制位向左移动指定的位数,右侧用0填充。例如,5 << 2 的结果是 20,因为 5 的二进制表示是 101,左移两位后变成 10100,即十进制的 20。左移几位就是相当于乘以2^n。
# 6.带符号右移>>
将操作数的二进制位向右移动指定的位数,根据最高位的值用0或1填充。这保持了有符号数的符号(正负号)。例如,-8 >> 1 的结果是 -4,因为 -8 的二进制表示是 11111111111111111111111111111000,带符号右移1位后变成 11111111111111111111111111111100,即十进制的 -4。
# 7.无符号右移>>>
类似于带符号右移,但不保留符号位,始终用0填充。这适用于无符号整数。例如,-8 >>> 1 的结果是 2147483644,因为它的二进制表示与带符号右移相同,但不考虑符号。
注意事项:
左移 1 位, 相当于原数字 * 2. 左移 N 位, 相当于原数字 * 2 的N次方. 右移 1 位, 相当于原数字 / 2. 右移 N 位, 相当于原数字 / 2 的N次方. 由于计算机计算移位效率高于计算乘除, 当某个代码正好乘除 2 的N次方的时候可以用移位运算代替. 移动负数位或者移位位数过大都没有意义.
# 三目运算符(条件运算符)
条件运算符只有一个:
表达式1 ? 表达式2 : 表达式3
当 表达式1 的值为 true 时, 整个表达式的值为 表达式2 的值;
当 表达式1 的值为 false 时, 整个表达式的值为 表达式3 的值.
也是 Java 中唯一的一个 三目运算符, 是条件判断语句的简化写法
int a = 10;
int b = 20;
int max = a > b ? a : b;
2
3
注意事项:
- 表达式2和表达式3的结果要是同类型的,除非能发生类型隐式类型转换
- . 表达式不能单独存在,其产生的结果必须要被使用
# 实例关系运算符
用于比较对象引用。
instanceof:检查对象是否是特定类的实例
如果运算符左侧变量所指的对象,是操作符右侧类或接口(class/interface)的一个对象,那么结果为真。
String name = "James";
boolean result = name instanceof String; // 由于 name 是 String 类型,所以返回真
2
如果被比较的对象兼容于右侧类型,该运算符仍然返回 true。
class Vehicle {}
public class Car extends Vehicle {
public static void main(String[] args){
Vehicle a = new Car();
boolean result = a instanceof Car;
System.out.println( result);
}
}
2
3
4
5
6
7
8
9
# 类型转换运算符
用于将值从一种类型转换为另一种类型。
(type):强制类型转换
long a = 10;
int b = (int)a;
2
# 运算符优先级
在一条表达式中,各个运算符可以混合起来进行运算,但是运算符的优先级不同,比如:* 和 / 的优先级要高于 +和 - ,有些情况下稍不注意,可能就会造成很大的麻烦。
只需要记住:在一条表达式中,各个运算符可以混合起来进行运算,但是运算符的优先级不同,比如:* 和 / 的优先级要高于 +和 - ,有些情况下稍不注意,可能就会造成很大的麻烦。
# String 字符串
# 概览
String 被声明为 final,因此它不可被继承。
内部使用 char 数组存储数据,该数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
2
3
4
# 不可变的好处
- 可以缓存 hash 值
因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算。
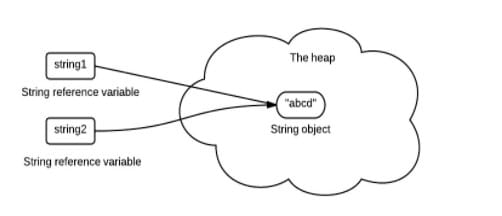
- String Pool 的需要
如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。
- 安全性
String 经常作为参数,String 不可变性可以保证参数不可变。例如在作为网络连接参数的情况下如果 String 是可变的,那么在网络连接过程中,String 被改变,改变 String 对象的那一方以为现在连接的是其它主机,而实际情况却不一定是。
- 线程安全
String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
# String StringBuffer StringBuilder
1. 可变性
- String 不可变
- StringBuffer 和 StringBuilder 可变
2. 线程安全
- String 不可变,因此是线程安全的
- StringBuilder 不是线程安全的
- StringBuffer 是线程安全的,内部使用 synchronized 进行同步
# String.intern()
使用 String.intern() 可以保证相同内容的字符串变量引用同一的内存对象。
下面示例中,s1 和 s2 采用 new String() 的方式新建了两个不同对象,而 s3 是通过 s1.intern() 方法取得一个对象引用。intern() 首先把 s1 引用的对象放到 String Pool(字符串常量池)中,然后返回这个对象引用。因此 s3 和 s1 引用的是同一个字符串常量池的对象。
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
System.out.println(s1.intern() == s3); // true
2
3
4
5
如果是采用 "bbb" 这种使用双引号的形式创建字符串实例,会自动地将新建的对象放入 String Pool 中。
String s4 = "bbb";
String s5 = "bbb";
System.out.println(s4 == s5); // true
2
3
- HotSpot中字符串常量池保存哪里?永久代?方法区还是堆区?
- 运行时常量池(Runtime Constant Pool)是虚拟机规范中是方法区的一部分,在加载类和结构到虚拟机后,就会创建对应的运行时常量池;而字符串常量池是这个过程中常量字符串的存放位置。所以从这个角度,字符串常量池属于虚拟机规范中的方法区,它是一个逻辑上的概念;而堆区,永久代以及元空间是实际的存放位置。
- 不同的虚拟机对虚拟机的规范(比如方法区)是不一样的,只有 HotSpot 才有永久代的概念。
- HotSpot也是发展的,由于一些问题在新窗口打开 (opens new window)的存在,HotSpot考虑逐渐去永久代,对于不同版本的JDK,实际的存储位置是有差异的,具体看如下表格:
| JDK版本 | 是否有永久代,字符串常量池放在哪里? | 方法区逻辑上规范,由哪些实际的部分实现的? |
|---|---|---|
| jdk1.6及之前 | 有永久代,运行时常量池(包括字符串常量池),静态变量存放在永久代上 | 这个时期方法区在HotSpot中是由永久代来实现的,以至于这个时期说方法区就是指永久代 |
| jdk1.7 | 有永久代,但已经逐步“去永久代”,字符串常量池、静态变量移除,保存在堆中; | 这个时期方法区在HotSpot中由永久代(类型信息、字段、方法、常量)和堆(字符串常量池、静态变量)共同实现 |
| jdk1.8及之后 | 取消永久代,类型信息、字段、方法、常量保存在本地内存的元空间,但字符串常量池、静态变量仍在堆中 | 这个时期方法区在HotSpot中由本地内存的元空间(类型信息、字段、方法、常量)和堆(字符串常量池、静态变量)共同实现 |
# 分支结构
if...else...
if (x <= 0) if (x == 0) sign = 0; else sign = -1;
switch...case...default
Scanner in = new Scanner(System.in);
System.out.printC'Select an option (1, 2, 3, 4) M);
int choice = in.nextlnt();
switch (choice)
{
case 1:
...
break;
case 2:
...
break;
case 3:
...
break;
case 4:
...
break;
default:
...
break;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 循环结构
for循环
for (int i = 1; i <= 10; i++)
{
.....
}
2
3
4
while循环
while (balance < goal){
balance += payment;
double interest = balance * interestRate / 100;
balance += interest;
years++;
}
2
3
4
5
6
7
do...while循环
这是一个需要至少执行一次的循环
do{
balance += payment;
double interest = balance * interestRate / 100;
balance += interest;
year-H-;
}
while (input.equals("N") );
2
3
4
5
6
7
for each 循环
intp a = new int[100]
for (int element : a)
System.out.println(element);
}
2
3
4
# 数组
数组是一种数据结构, 用来存储同一类型值的集合。
数组的定义:
int[] a = new int[100];
插入值:
for (int i = 0; i < 100; i++){
a[i] = i ;
}
//我们可以通过下标的方式去获取到指定数组位置的值。获取最后一个值:int lastValue=a[99];
2
3
4
5
6
7
注意下标不可以超过数组长度。不然的话就会发生数组下标越界异常
在声明数组之后,每一个数组对应的值为该数据类型的默认值。
/**
* 测试数组定义会自动填充默认值
* @author CurleyG
* @date 2024/10/6 16:37
*/
public class ArrayTest {
public static void main(String[] args) {
int[] a = new int[100];
System.out.println(a[99]==0);
boolean[] b = new boolean[100];
System.out.println(!b[99]);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//for-each循环
public class ArrayForEach {
public static void main(String[] args) {
int[] a = new int[100];
//for循环
for (int i = 0; i < 100; i++){
a[i] = i ;
}
for (int i : a) {
System.out.println(i);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
**数组初始化 **
int[] smallPrimes = { 2, 3, 5, 7, 11, 13 };
int[] smallPrimes =new int[]{ 17, 19, 23, 29, 31, 37 }
数组拷贝
我们知道数组是应用类型,也就是说我们将一个数组赋值给另外一个数组,就是就是改变另外一个数组的引用地址的指向。
public class ArrayTestCopy {
public static void main(String[] args) {
int[] a = new int[100];
int[] b=a;
a[0]=9;
System.out.println(a[0]);
System.out.println(b[0]);
}
}
2
3
4
5
6
7
8
9
Arrays.copyOf
public class ArrayTestCopy {
public static void main(String[] args) {
int[] luckyNumbers = {4, 8, 15, 16, 23, 42} ;
//第一个参数是数组对象,第二个是指定数组长度
int[] copiedLuckyNumbers = Arrays.copyOf(luckyNumbers, luckyNumbers.length*2) ;
System.out.println(Arrays.toString(copiedLuckyNumbers));
}
}
2
3
4
5
6
7
8
如果第二个参数是小于原来的数组长度的那么只会拷贝最前面的数据。如果第二个参数大于原本的数组长度那么多出来的位置就会是原本数据类型的默认值。
测试数组长度不够的问题
public class ArrayTestCopy {
public static void main(String[] args) {
int[] luckyNumbers = {4, 8, 15, 16, 23, 42} ;
int[] copiedLuckyNumbers = Arrays.copyOf(luckyNumbers, luckyNumbers.length-1) ;
System.out.println(Arrays.toString(copiedLuckyNumbers));
}
}
2
3
4
5
6
7
8
数组排序
/**
* 此程序演示了数组操作.
* @version 1.20 2004-02-10
* @author Cay Horstmann
*/
public class LotteryDrawing
{
public static void main(String[] args)
{
Scanner in = new Scanner(System.in);
System.out.print("您需要抽出多少个号码? ");
int k = in.nextInt();
System.out.print("您可以抽到的最大数字是多少? ");
int n = in.nextInt();
// 定义了一个n长度的数组
int[] numbers = new int[n];
// 初始化数组
for (int i = 0; i < numbers.length; i++)
numbers[i] = i + 1;
// 绘制 k 个数字并将它们放入第二个数组中
int[] result = new int[k];
for (int i = 0; i < result.length; i++)
{
//制作一个介于 0 和 n - 1 之间的随机索引 Math.random范围是[0-1) 之间[0-(n-1)
int r = (int) (Math.random() * n);
// 在随机位置选取元素
result[i] = numbers[r];
// 将最后一个元素移动到 Random 位置
numbers[r] = numbers[n - 1];
n--;
}
// 打印排序数组
Arrays.sort(result);
System.out.println("投注以下组合。它会让你变得富有!");
for (int r : result)
System.out.println(r);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
数组Arrays常用方法
1. static String toString(type[] a)
返回包含 a 中数据元素的字符串, 这些数据元素被放在括号内, 并用逗号分隔。
参数: a 类型为 int、long、short、char、 byte、boolean、float 或 double 的数组
2.static type copyOf(type[] a, int length)//原本数组,数组长度
3. static type copyOfRange(type[] a , int start , int end) //原本数据,起始下标,结束下标
4.static void sort(type[] a)
采用优化的快速排序算法对数组进行排序。
5.static int binarySearch(type[] a , type v)
6.static int binarySearch(type[] a, int start, int end , type v)
采用二分搜索算法查找值 v。如果查找成功, 则返回相应的下标值; 否则, 返回一个
负数值。r -r-1 是为保持 a 有序 v 应插入的位置。
参数: a 类型为 int、 long、 short、 char、 byte、 boolean 、 float 或 double 的有
序数组。
start 起始下标(包含这个值)。
end 终止下标(不包含这个值。)
v 同 a 的数据元素类型相同的值。
7.static void fill(type[] a , type v)
将数组的所有数据元素值设置为 V。
参数: a 类型为 int、 long、short、char、byte、boolean 、 float 或 double 的数组。
v 与 a 数据元素类型相同的一个值
8. static boolean equals(type[] a, type[] b)
如果两个数组大小相同, 并且下标相同的元素都对应相等, 返回 true。
参数: a、 b 类型为 int、long、short、char、byte、boolean、float 或 double 的两个数组。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Arrays.sort底层原理 (opens new window):有关于算法的知识
多维数组
初始化
int[][] magicSquare =
{
{16, 3, 2, 13},
{5, 10, 11, 8},
(9, 6, 7, 12},
{4, 15, 14, 1}
}
获取值 magicSquare[0][1] 得到 3
2
3
4
5
6
7
8
# 常见的字符集
# ASCLL字符集
使用一个字节标识一个字符,首尾是0,总共表示128个字符,对于美国佬够用了。
我们知道计算机是美国人发明的,为了能够在计算机中保存数据又因为计算机只认识0和1,所以就创造除了ASCLL这种字符集。由英文字母(大小写),数字和一些特殊符号组件的字符集。
每一个字符对应一个码点,比如0对应48,A对应65,a对应97,这样的对应关系映射我们就成为字符集
但是它怎么存储在计算机中的呢?其实很简单我们一个字节就可以表示玩所以的字符集中的字符。即直接将对应的码点值转换为二进制,不够一个字节8位的采取补0,这种从码点--->二进制存储的过程我们就称为编码
从磁盘读取字节数据---->显示字符 这个过程称为解码
# GBK字符集
对于我们中国来说够本不够我们塞牙缝,我们中国汉字博大精深。所有我们就创造除了GBK字符集。
汉字编码字符集,包含2万多个汉字等字符,GBK中的一个中文字符编码成两个字节存储。但是这个字符集是完全兼容ASCLL字符集
相同的字符在ASCLL字符集中的码点值与在GBK字符集相同
那么问题来了?中文字符2个字节,但是ASCLL中的字符一个字节,那我们怎么区分那个为汉字,那个为字符呢?
例如:我a你
难道计算机存储为 xxxxxxxx xxxxxxx|0xxxxxx|xxxxxxx xxxxxxx ?
那我解码的时候可以这样子划分 xxxxxxxx|xxxxxxx 0xxxxxx|xxxxxxx xxxxxxx 这样得到的内容不一致了
实际上GBK有一个规定:汉字的第一个字节的第一位必须是1,存储在计算机为 1xxxxxxx xxxxxxx|0xxxxxx|1xxxxxx xxxxxxx。这样我们解码的时候喷到第一个字节为1我们就读取下一个字节一起解码,如果为0直接解码。
# Unicode字符集
统一码,也叫万国码。
如果每一个国家都去编写自己的字符集,那么就会出现大量的乱码问题。国际组织就站出来说:你们也不要瞎搞了,我来统一一下字符集。可以容纳时间上所有的文字和符号。
根据这种字符集也产生了不同的编码方案
UTF-32编码
简单粗暴的把码点的值。4个字节的二进制值。确定是:比如我一个A其实一个字节就可以表示了。你却用4个字节来存储,大大的降低了存储的利用率,同时通信效率也会降低。
UTF-8
是Unicode字符集的一种编码方案,采取可变长编码方案,共分1个字节,2个字节,3个字节,4个字节
英文字符,数字占1个字节(兼容ASCLL),汉字占用3个字节
那它是怎么区分那几个字节为一个字符呢?
这里采用了特殊的前缀码来表示那几个字节为一个字符。
ASCII字符范围,字节由零开始 一个字节
第一个字节由110开始,接着的字节由10开始 2个字节
第一个字节由1110开始,接着的字节由10开始 3个字节
将由11110开始,接着的字节由10开始 4个字节
← 第01章:Java概述 第03章:面向对象 →
